
Maschinelles Lernen beschleunigt die Peptidreinigung
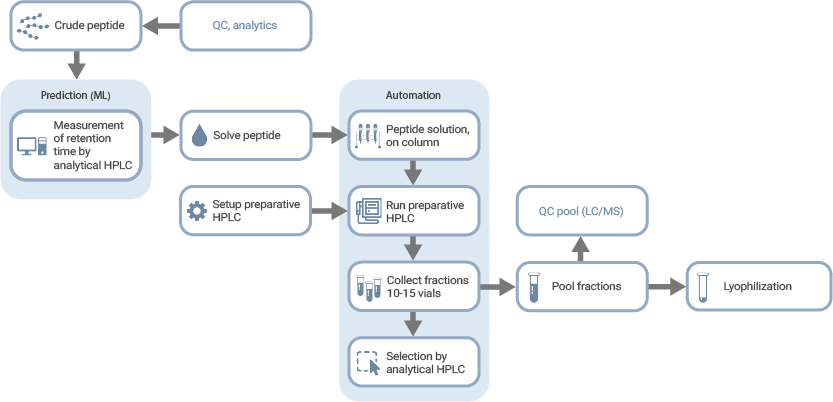
Synthetische Peptide sind aus moderner Forschung, Diagnostik und der Entwicklung neuer Therapien nicht mehr wegzudenken. Ob Impfstoffdesign, Wirkstoffscreening oder personalisierte Medizin – der Bedarf an Peptiden wächst rasant. Gleichzeitig steigen die Anforderungen an Geschwindigkeit, Reproduzierbarkeit und Prozesssicherheit in Laboren weltweit. Während die Peptidsynthese heute weitgehend automatisiert und skalierbar ist, bleibt ein Prozessschritt häufig ein limitierender Faktor: die Reinigung. Traditionell erfordert die Peptidaufreinigung zeitaufwendige analytische Scout-Läufe, manuelle Gradientenfestlegung und eine händische Fraktionssammlung. Besonders bei vielen oder wechselnden Sequenzen führt dieses Vorgehen zu hohem Arbeitsaufwand und begrenzt den Durchsatz im Labor.
Genau hier setzt unser neuer Ansatz an
Mithilfe von Machine Learning vereinfachen und automatisieren wir die Peptidreinigung konsequent. Ein auf 1.311 Peptidsequenzen trainiertes Modell sagt die Retentionszeit einzelner Peptide präzise voraus. Grundlage dafür sind physikochemische Eigenschaften wie Hydrophobizität, Nettoladung, Sequenzlänge und das Aminosäureprofil. Zum Einsatz kommt ein Support-Vector-Regression-Modell mit hoher Vorhersagegenauigkeit (R² = 0,89; MAE = 0,18 Minuten). Die vorhergesagte Retentionszeit wird direkt in den automatisierten Semi-Prep-HPLC-Prozess integriert. Proben werden injiziert, chromatografisch getrennt und ausschließlich Fraktionen im berechneten Zeitfenster gesammelt. Analytische Vorversuche zur Retentionszeitbestimmung entfallen vollständig.
Das Ergebnis
Reinheiten von über 80 Prozent bei durchschnittlichen Ausbeuten von rund 82 Prozent – bei deutlich reduziertem Zeit- und Arbeitsaufwand. Damit lässt sich die Peptidreinigung erstmals datengetrieben planen und reproduzierbar skalieren. Machine Learning wird so zu einem praktischen Werkzeug, um Engpässe in der Peptidproduktion aufzulösen und Hochdurchsatzprozesse effizient umzusetzen.
